Presentamos alternativas de soluciones de arquitectura, combinando servicios de Amazon Web Services y procesos automatizados de Novis como NovisCloud, para permitir a nuestros clientes la optimización de sus costos de sus servicios para SAP® en el Cloud Público.
Introducción
La pandemia global del COVID-19 ha traído serias consecuencias económicas que están afectando los mercados y, en consecuencia, los resultados económicos de muchas empresas. Hoy más que nunca se vuelve importante buscar ahorros en donde sea posible. En este contexto, las áreas de TI tienen una fuerte presión por reducir sus costos y adecuarse a las nuevas condiciones de la economía.
La infraestructura elástica de Amazon Web Services ofrece nuevas posibilidades para entregar niveles de disponibilidad y protección adecuados para las necesidades de muchas empresas sin recurrir a configuraciones complejas y costosas de alta disponibilidad y recuperación de desastres. Este documento presenta alternativas de soluciones de arquitectura, combinando servicios de Amazon Web Services y procesos automatizados de Novis, para permitir a nuestros clientes la optimización de sus costos de sus servicios para SAP en el Cloud Público.
Plataforma NovisCloud
La obtención de los beneficios del Cloud requiere enfoques radicalmente distintos a las operaciones tradicionales On Premise. Por esta razón decidimos crear NovisCloud, una plataforma de automatización de Servicios SAP en el Cloud. Esta plataforma ha sido concebida bajo la visión de dar una experiencia tipo Cloud para aplicaciones SAP en AWS, que se estructura en torno a los siguientes pilares:

NovisCloud juega un rol esencial para mejorar la disponibilidad de SAP en AWS a través de la integración de métricas de monitoreo de SAP en CloudWatch (plataforma de monitoreo de AWS) y la implementación de mecanismos automatizados de recuperación de los servicios ante distintos escenarios de falla (auto-healing), extendiendo las capacidades de recuperación nativas de AWS hacia las aplicaciones SAP. Por medio de esta plataforma, es posible realizar orquestación de procesos de recuperación y validaciones automatizadas de los sistemas recuperados.
Arquitectura SAP
Los sistemas basados en el servidor de aplicación SAP Netweaver ABAP tienen una arquitectura monolítica o stateful, esto implica que la información de la sesión o estado de cada proceso, son almacenados en el servidor de aplicación donde es procesado.
Cuando un usuario se conecta a SAP, mediante SAPGUI o navegador, la aplicación realiza un proceso de balanceo y direcciona el usuario a un servidor de aplicación, donde permanece conectado, hasta que finaliza su sesión (algunos usuarios suelen estar todo el día trabajando en la misma sesión, conectado al mismo servidor de aplicación).
Esta característica provoca que la caída de un servidor de aplicación impacta directamente el trabajo de un usuario o proceso. El usuario (o proceso) afectado tendrá que volver a iniciar sesión (o relanzar el proceso) y reanudar el trabajo desde la última transacción no finalizada.
Alta Disponibilidad, Tolerancia a Fallas y Recuperación de Desastres
- Alta Disponibilidad es la capacidad de recuperar los servicios de TI frente a una falla en un tiempo acotado mediante un procedimiento probado y automatizado que considere la detección del evento de fallo, y la recuperación de los servicios. Ante una falla, es posible que exista una pérdida del servicio que debe mantenerse dentro del RTO (Recovery Time Objective) acordado con la organización. En general se espera que la recuperación de servicio en un escenario de Alta Disponibilidad no involucre pérdida de datos (RPO = 0).
- Tolerancia a Fallas es la capacidad de soportar algunos escenarios de fallas sin interrupción del servicio TI.
- Recuperación de Desastres (DR, por sus siglas en inglés) es la capacidad de recuperarse de un desastre, un elemento que genera un daño permanente o prolongado en la infraestructura TI.
Infraestructura Global en Amazon Web Services
Amazon Web Services (AWS) ofrece los servicios de Cómputo y Almacenamiento de bloque de alto rendimiento desde un conjunto de Centro de Datos distribuidos en el planeta (https://aws.amazon.com/es/about-aws/global-infrastructure/regions_az/).
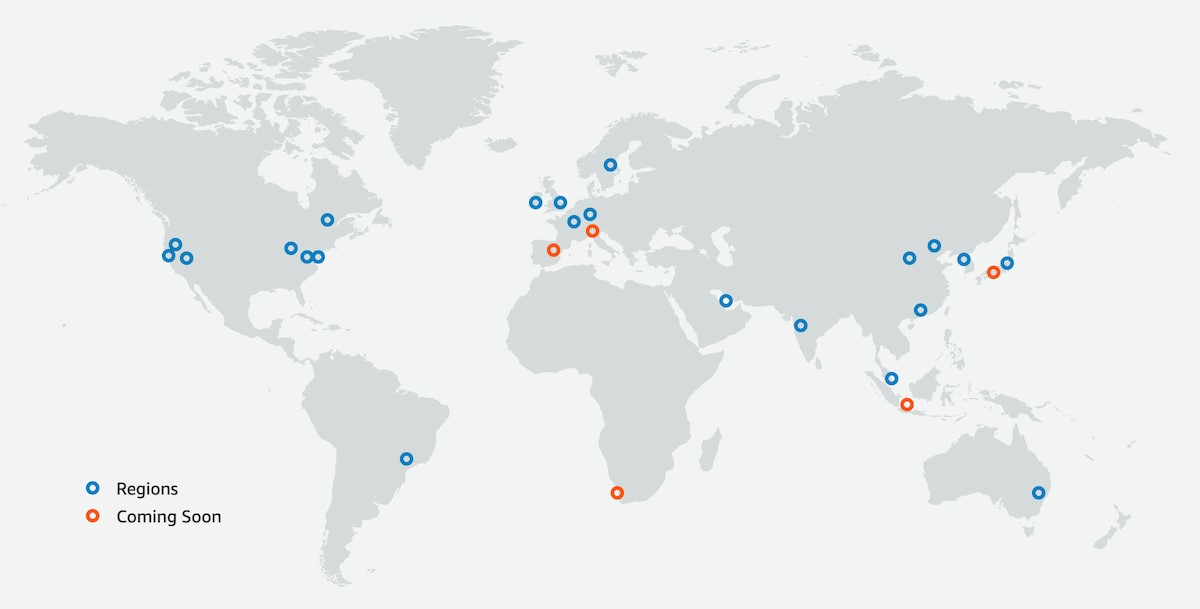
AWS tiene el concepto de una Región como una ubicación física, donde agrupan los centros de datos. Cada grupo de centros de datos lógicos es identificado como una zona de disponibilidad (AZ). Cada región de AWS consta de varias AZ aisladas y separadas físicamente dentro de un área geográfica. A diferencia de otros proveedores de nube, que a menudo definen una región como un solo centro de datos, el diseño múltiple de AZ de cada región de AWS ofrece ventajas para los clientes. Cada AZ tiene alimentación, refrigeración y seguridad física independientes y está conectada a través de redes redundantes de latencia ultrabaja.
Los diferentes servicios de AWS pueden tener redundancias a nivel global, regional y zonal. Esto permite construir arquitecturas y servicios con diferentes niveles de protección.
Arquitecturas de Referencia
Las siguientes arquitecturas de referencia son diseños simplificados para sistemas SAP Netweaver con base de datos SAP HANA (e.g. S/4 HANA, Suite on HANA), que permiten demostrar niveles de protección para diferentes escenarios de falla.
Los recursos de cómputo están dimensionados como una referencia inicial para entornos productivos. Para mayor información sobre los tipos de instancias recomendados para SAP HANA en AWS visita SAP HANA on the AWS Cloud: Quick Start Reference Deployment. Para mayor información sobre los tipos de instancias recomendadas para aplicaciones SAP Netweaver visita la nota SAP 1656099 – SAP Applications on AWS: Supported DB/OS and AWS EC2 products.
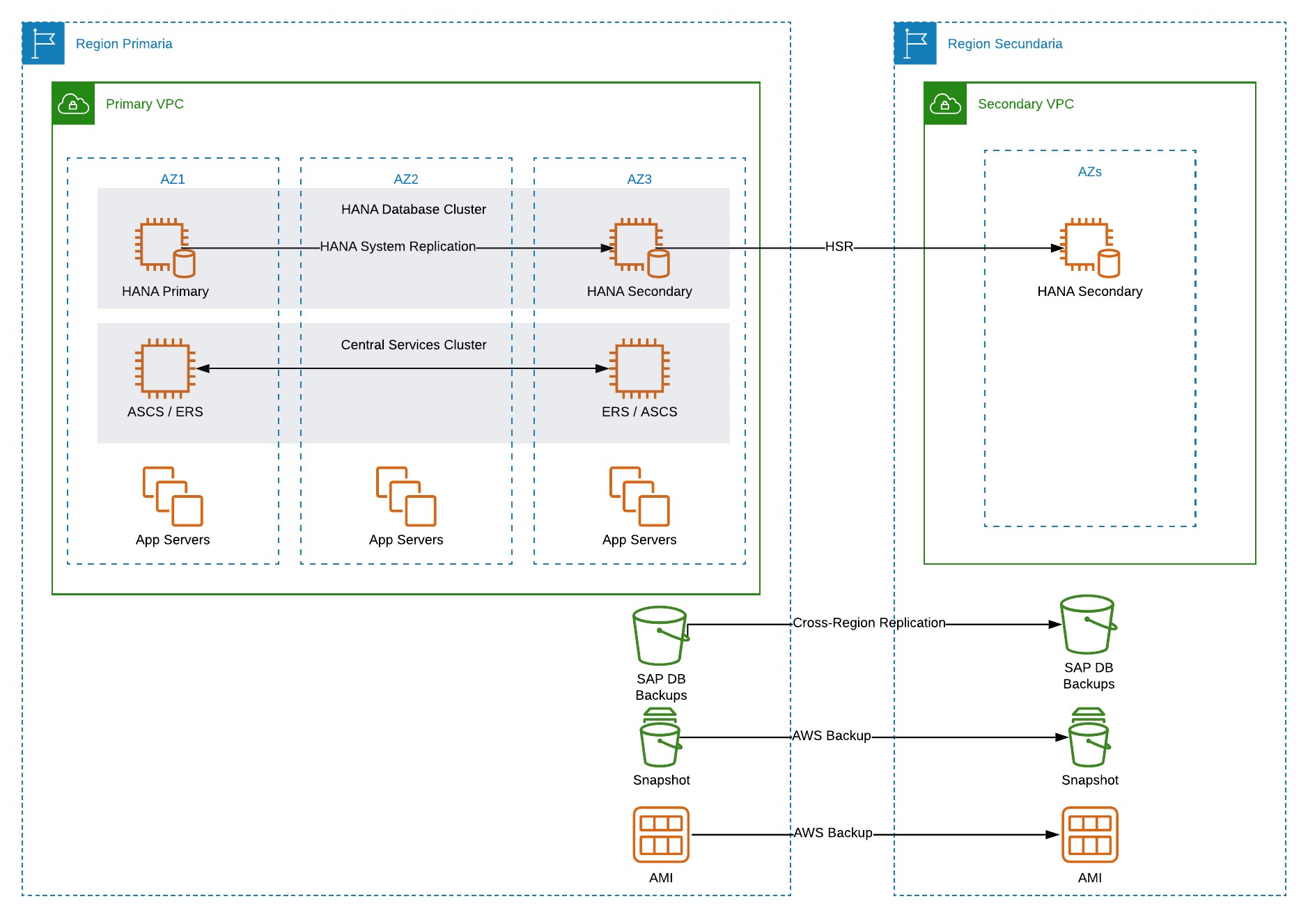
Para los sistemas de misión crítica, SAP recomienda la implementación de una arquitectura de alta disponibilidad que involucra la separación de los servicios de NW en distintos servidores o máquinas virtuales (base de datos, servicios centrales y servidores de aplicación), la protección de los puntos únicos de falla mediante mecanismos de clúster (base de datos y servicios centrales) y la protección de otros componentes mediante redundancia. Adicionalmente, se requiere implementar una solución de recuperación ante desastres que involucra la replicación de la base de datos y de los respaldos de servidores hacia un datacenter de contingencia. Este escenario, que se representa más adelante como Arquitectura 1, entrega los más altos niveles de protección de los servicios, pero es de alta complejidad y costos elevados.
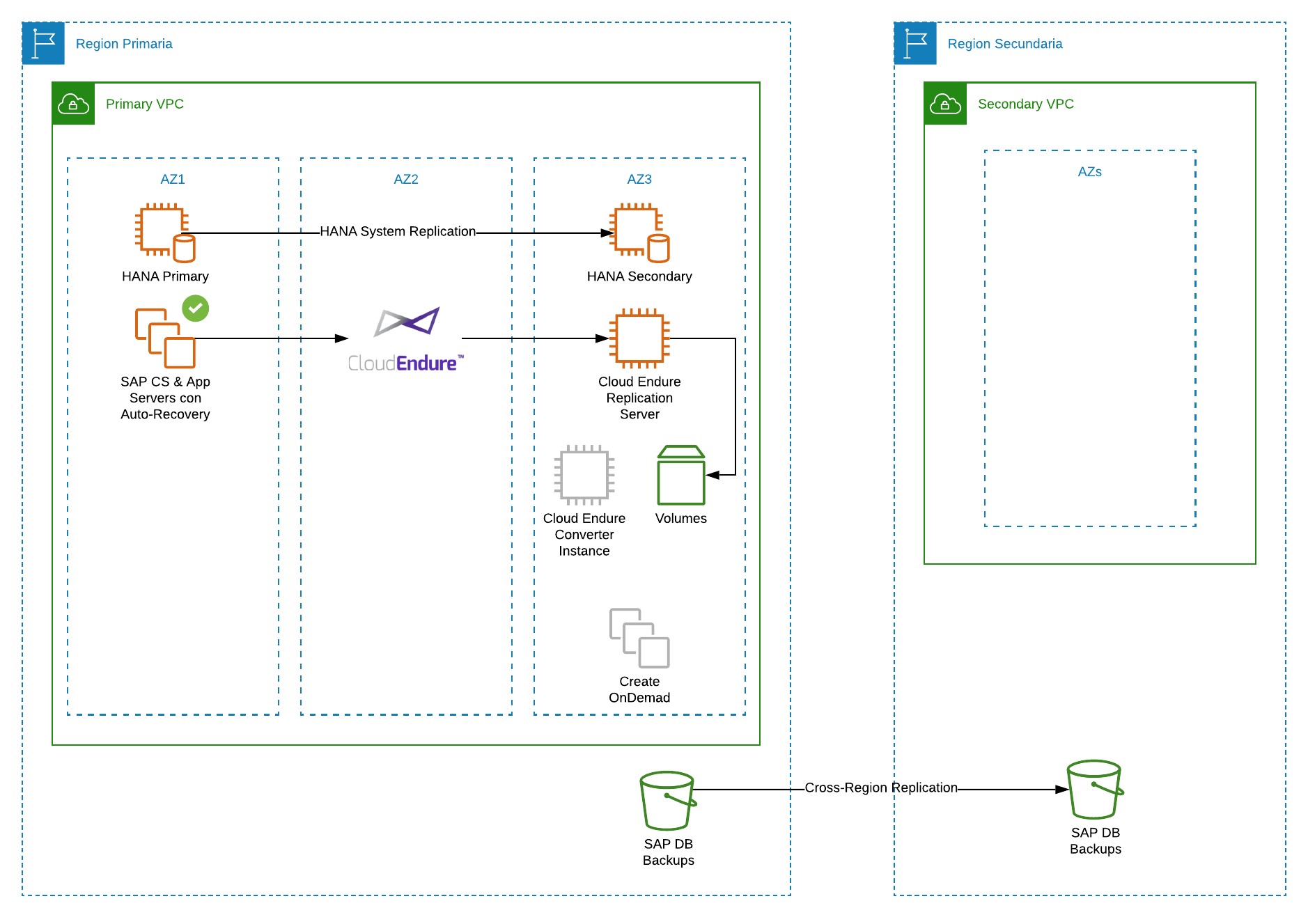
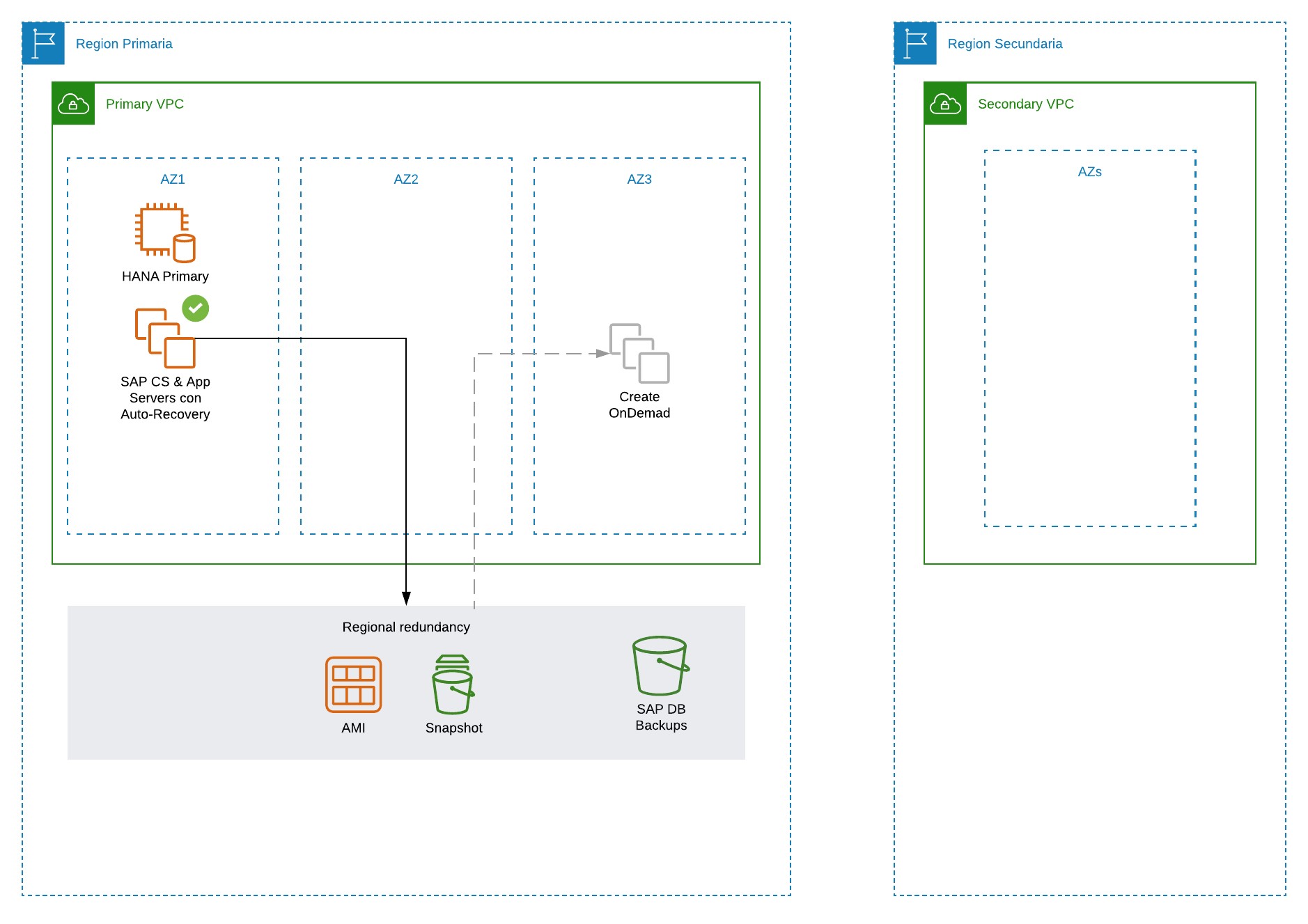
Novis propone dos arquitecturas alternativas que a pesar de no igualar los SLAs de la arquitectura anterior, entregan niveles de servicio elevados comparados con soluciones On Premise y permiten obtener importantes reducciones en costos. La arquitectura 2 involucra la replicación de la base de datos a una instancia de menor tamaño y la replicación de los servidores de aplicación utilizando CloudEndure. La arquitectura 3 utiliza las capacidades nativas de recuperación de AWS para restablecer el servicio ante una falla de una instancia y la redundancia de los almacenamientos para respaldos (AWS S3 y EBS snapshots) para la recuperación de los servicios ante la falla de una Availability Zone.
A continuación, se presentan los diagramas de infraestructura AWS para cada una de estas arquitecturas.
Arquitectura 1: AVANZADA
Arquitectura 2: ESTÁNDAR
Arquitectura 3: BÁSICA
Escenarios de fallas
Existen diferentes escenarios que pueden afectar el servicio de una aplicación SAP para un usuario final, desde un cambio en la funcionalidad de la aplicación hasta la estación de trabajo del usuario.
En esta publicación revisaremos los tres escenarios de fallas más representativos al evaluar los conceptos de Alta Disponibilidad, Tolerancia a Fallos y Recuperación de Desastres:
- A. Falla de una instancia Amazon EC2
- B. Falla de una Zona de Disponibilidad AWS (AZ)
- C. Falla de una Región AWS
|
A.
Instancia EC2 |
B.
Zona de Disponibilidad AWS |
C.
Región |
Arquitectura 1
Avanzada
(Costo 300%) |
RPO: 0
RTO: 3 min |
RPO: 0
RTO: 3 min |
RPO: 5 min
RTO: 1 hora |
Arquitectura 2
Estándar
(Costo 150%) |
RPO: 0
RTO: 10 min |
RPO: 0
RTO: 20 min |
RPO: 30 min
RTO: 2 – 5 horas
Observaciones: Dependiendo del tamaño de la Base Datos |
Arquitectura 3
Básica
(Costo 100%) |
RPO: 0
RTO: 10 min |
RPO: 20 min
RTO: 1 a 4 horas
Observaciones: Dependiendo del tamaño de la Base de Datos |
RPO: N/A
RTO: N/A |
A. Falla de una instancia EC2
Arquitectura 1
En caso de caída de una instancia EC2 de Base de Datos la réplica síncrona de datos permite que el cambio del nodo primario HANA no permita pérdida de información y los usuarios solo experimentarán degradación del servicio durante los minutos que dura el proceso de failover.
En caso de caída de una instancia EC2 de Servicios Centrales SAP, la réplica de la tabla de bloqueo asegura que la información persista en el host secundario y el tráfico es redirigido. Los usuarios solo experimentarán degradación del servicio durante los minutos que dura el proceso de failover.
En caso de caída de una instancia EC2 de un Servidor de Aplicación, los usuarios y procesos en ejecución se desconectarán. Los usuarios y procesos conectados a otros servidores de aplicación no son afectados. Al volver a conectarse serán dirigidos a los Servidores de Aplicación disponibles.
Arquitectura 2
En caso de caída de una instancia EC2 de Base de Datos la réplica síncrona de datos permite que el cambio del nodo primario HANA no permita pérdida de información y los usuarios solo experimentarán degradación del servicio durante los minutos que dura el proceso de failover. El failover de la base de datos se realiza mediante funcionalidad de NovisCloud que permite realizar el resizing de la instancia EC2 y la ejecución del failover a nivel de SAP HANA.
En caso de caída de una instancia EC2 de Servicios Centrales SAP o Servidores de Aplicación, los usuarios y procesos en ejecución serán cancelados hasta que se reinicien las máquinas virtuales (automatizado con Auto-Recovery) y los procesos SAP están disponibles nuevamente. NovisCloud maneja la orquestación del proceso de recuperación del aplicativo SAP y la validación de dependencias entre los distintos servicios.
Arquitectura 3
En caso de caída de una instancia EC2 de Base de Datos, los usuarios y procesos en ejecución experimentarán degradación en el servicio hasta que hasta que se reinicien las máquinas virtuales (automatizado con Auto-Recovery) y el servicio de Base de Datos esté disponible nuevamente
En caso de caída de una instancia EC2 de Servicios Centrales SAP o Servidores de Aplicación, los usuarios y procesos en ejecución serán cancelados hasta que se reinicien las máquinas virtuales (automatizado con Auto-Recovery) y los procesos SAP están disponibles nuevamente. NovisCloud maneja la orquestación del proceso de recuperación del aplicativo SAP y la validación de dependencias entre los distintos servicios.
B. Falla de una Zona de Disponibilidad AWS
Arquitectura 1
En caso de que la caída de una zona de disponibilidad, los mecanismos de clúster de Base de datos y Servicios Centrales permiten la continuidad de los servicios descrito anteriormente.
Para los Servidores de Aplicación se considera la distribución del 150% de los recursos necesarios para una operación normal distribuido entre 3 zonas de disponibilidad. De ese modo ante la falla de una de las zonas, los recursos disponibles soportarán el 100% de las solicitudes de procesos y usuarios.
Arquitectura 2
En caso de la caída de una zona de disponibilidad, la réplica síncrona de datos de HANA permite que el cambio del nodo primario HANA no permita pérdida de información. Para las instancias de Servicios Centrales y Servidores de Aplicación SAP Cloud Endure realiza la generación de instantáneas (snapshots) de los volúmenes presentados. Estas instantáneas son replicadas a nivel regional, por lo que están disponibles en todas las zonas de disponibilidad para crear recrear los servidores afectados a partir de la última instantánea. La gestión de la infraestructura y sus características es gestionada por NovisCloud, para permitir ejecuciones ya documentadas y parametrizadas durante el incidente.
Arquitectura 3
En caso de la caída de una zona de disponibilidad, los respaldos de la base de datos son almacenados en S3, replicando esta información a nivel regional, por lo que después de reconstruir las instancias EC2 desde las imágenes AMI y los discos desde snaphost, se ejecuta el proceso de recuperación (restore) de la base de datos hasta el último log disponible en S3. La gestión de la infraestructura y sus características es gestionada por NovisCloud, para permitir ejecuciones ya documentadas y parametrizadas durante el incidente.
C. Falla de una Región
Arquitectura 1
En caso de la falla de una región, la réplica asíncrona de datos de HANA permite que el cambio del nodo primario HANA tenga un mínimo de pérdida de información transaccional. Las imágenes e instantáneas ya disponibles en la región de destino permiten recrear la infraestructura de modo automatizado desde la ultima información replicada.
La gestión de la infraestructura y sus características es gestionada por NovisCloud, para permitir ejecuciones ya documentadas y parametrizadas durante el incidente.
Arquitectura 2
En caso de una falla de una región, los respaldos de Base de Datos replicados a la región secundaria permiten la reconstrucción de infraestructura con las mismas características originales, pero sin información que no sea almacenada en la base de datos (deployments en el caso de Stack JAVA y archivos de control en el caso de Stack ABAP).
La gestión de la infraestructura y sus características es gestionada por NovisCloud, para permitir ejecuciones ya documentadas y parametrizadas durante el incidente.
Arquitectura 3
En caso de una falla de una región, solo está disponible la información de características de infraestructura, pero no es posible recuperar la información de la aplicación.
CONCLUSIÓN
Al reducir los puntos de réplica, aumentan los puntos únicos de falla y disminuyen los niveles objetivo de recuperación y pérdida de información. Sin embargo, los objetivos de servicios en el escenario más básico, compiten con arquitecturas OnPremise optimizando los costos del departamento de TI de clientes que quieren aprovechar los servicios de nube, migrando sus sistemas SAP a AWS.
Para más información de nuestros servicios, le invitamos a contactarnos.
Nota de: Cristian Marin, SubDirector de Tecnología y Patricio Renner, Chief Technology Officer
 Chile
Chile
 México
México
 Estados Unidos
Estados Unidos
